
ChatGPT Terms of Service Explained for Businesses: Updated Terms
OpenAI recently updated its Terms of Use, Services Agreement, and Privacy Policy. OpenAI’s ChatGPT is not governed by one contract, but by five separate legal documents. Which ones apply to you depends on which plan you use. You might wonder: why does this matter? For example, it might surprise you that the ‘ Pro’ plan is a consumer contract where OpenAI will use your data to train their models. Many organizations get this wrong.. This is why we have written this article to explain the OpenAI ChatGPT terms. The same questions keep coming up: which ChatGPT terms apply, how do the documents fit together, and what does this mean for users?
The most common question we get: does ChatGPT train on my data? The short answer is yes, unless you are on a Business or Enterprise plan, or have manually opted out in your account settings. That is where most individuals and organisations run into problems. Not because the terms are hidden, but because nobody explains how the five documents fit together and which one applies to them.
Instead of one contract, OpenAI uses a layered framework. A Terms of Use or Services Agreement as the primary contract, combined with Usage Policies, Service-Specific Terms, and a Data Processing Addendum – each covering different aspects of the relationship. This article explains how they connect, which one applies to you, and what it means in practice for individuals and businesses using ChatGPT
TL;DR
- Will ChatGPT train on your data? Yes, except if you opt out or if you have a business contract
- The ChatGPT Terms of Service are part of a broader OpenAI contract structure made up of multiple interconnected documents.
- Different terms apply depending on whether you use ChatGPT as an individual or under a business agreement.
- The “Pro” Trap: Pro is classified as a Consumer account. By default, this model trains on your data, unless you manually opt out.
- For organisations, the OpenAI Services Agreement is the primary contract for e.g. API and enterprise use.
- Don’t forget that there are specific policies, service terms & addenda that contain a lot of operational obligations.

Why Do the ChatGPT Terms of Service Matter?
AI vendors like OpenAI, Claude, Gemini but also SaaS/Software providers like Salesforce, Uber, Atlassian, Microsoft,etc. increasingly rely on layered contracts that incorporate multiple documents by reference. This normally includes an order form, a Master Services Agreement, general terms, service-specific terms and policies and addenda. When it comes to OpenAI that is no exception.
What really matters in practice is the distinction between consumer (individual) use and business use, as different terms apply to each.
- Consumer vs business use determines your risk position: Even when employees use ChatGPT for work, they may still fall under consumer Terms of Use. In practice, this means different data usage rules, liability allocation, and protections apply than the organization expects. We see similar issues across other AI providers (see our article on Claude AI: Anthropic’s Claude AI Updates – Impact on Privacy & Confidentiality). For business use, organizations should ensure employees only use OpenAI services under company-approved terms.
- Layered contracts mean obligations are spread across documents: Different documents govern different aspects of the relationship. Teams often assume one set of terms applies, while key obligations sit in policies or service-specific terms. Because these documents are incorporated by reference and updated regularly, obligations can change without renegotiation. This creates operational risk if no one actively monitors updates.
This type of contractual framework is not uncommon. Many large Tech, SaaS and AI providers use similar contractual structures. Nonetheless, the interlinked nature of these contracts means that each document creates distinct rights and obligations that operate together as a whole. This makes it interesting to understand these contracts more in-depth.
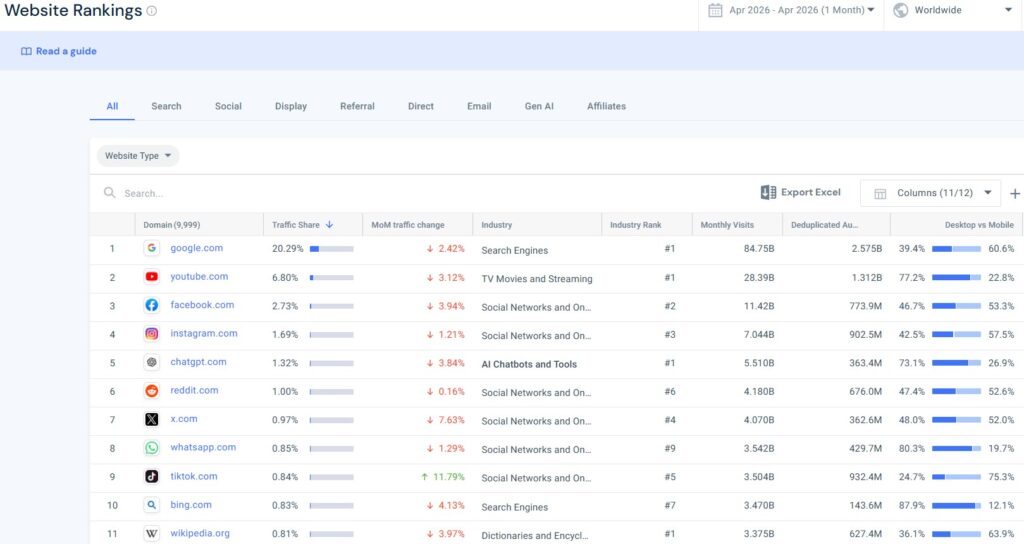
According to Similarweb’s Top Websites Ranking April 2026 (see here), ChatGPT is one of the most used websites globally.. This makes understanding of their governing terms particularly interesting.
ChatGPT and OpenAI Contract Structure Explained
At a high level, OpenAI does not rely on a single contract. Instead, it uses a layered contractual framework where multiple documents operate together. This approach is standard across SaaS and AI providers, but it requires a different way of reading contracts. Rather than reviewing one agreement in isolation, organisations need to understand how several documents interact and which one takes precedence in practice. (for more details, see OpenAI’s article here)
The three general terms that can be applicable revolve around three primary actors:
- Individuals (residing in the EEA),
- Individuals (residing outside the EEA), or
- Businesses (non-specific location).
The key is to understand that only one of these above documents forms part of the contractual framework between you (the company you work at) and OpenAI. Moreover, these general terms acts as a connection point which pulls in additional policies and addenda. Because, most importantly, these governing agreements do not stand alone as OpenAI’s contractual structure relies heavily on incorporation by reference. However, as a basic starting point, the general terms and data privacy related policies deserves an in-depth explanation on its own.
OpenAI’s explanation about the new terms is unfortunately unclear and in some places incomplete (see for yourself here), This is exactly why we wrote this article. OpenAI maintains a dedicated help article explaining their Terms of Service updates. Given that 900 million people use ChatGPT every week, you would expect this to be a reliable reference point. It is not — the article references conflicting dates and leaves the consumer/business distinction unexplained entirely.

ChatGPT Terms of Service Explained – How the Documents Actually Fit Together
Below we explain the full structure in plain language. OpenAI’s framework is built on five documents, each covering a different part of the relationship between you and OpenAI. Understanding how they connect is what most articles, including OpenAI’s own, fail to do clearly. Here is the version that actually makes sense.
Terms of Use (Individual Use)
The OpenAI Terms of Use govern individual use of ChatGPT and other OpenAI services. In practice, these are the default terms that apply unless an organisation has entered into a business agreement. This distinction is critical because many employees use ChatGPT in a professional context while still operating under individual terms.
From a legal and commercial perspective, the Terms of Use focus on access and behaviour. They define who can use the service, what constitutes acceptable use, and how content is treated. They also include limitations of liability and disclaimers that are typical for consumer-facing platforms. However, they are not designed to address enterprise-level concerns such as negotiated liability caps, audit rights, or structured data protection obligations.
As a result, organisations that rely on ChatGPT without moving to a business setup may unknowingly accept a risk profile that is materially different from what they would expect in a typical vendor relationship. This is not a drafting issue—it is a structural one.
Differences Europe Terms of Use vs Terms of Use
For individuals using OpenAI’s services, which is dependent on which account plan you are using, there is only one distinction in which contractual framework applies. The determining factor for whether the Europe Terms of Use or the Terms of Use is applicable is where you live. If you reside in the EEA, Switzerland or the UK, the Europe Terms of Use governs the usage of for example ChatGPT. On the contrary, if you reside outside of the EEA, Switzerland, or the UK, the Terms of Use are applicable.
Both these agreements governs individual’s use of OpenAI’s services. Structurally, both contracts covers the same services, places the same user obligations on the user and ensures that users retain rights to their input/output for example.
A few differences highlighted:
- Contracting parties differ depending on your location as residents in the EEA or Switzerland contract with OpenAI Ireland Ltd, while UK and US residents enters into a contractual relationship with OpenAI OpCo LLC.
- Content of terms, linked to local legal requirements. For example, the Terms of Use, applicable on UK and US residents, allow arbitration while the Europe Terms of Use doesn’t. oth the Europe Terms of Use and the Terms of Use specify that the Privacy Policy is not a part of the contract, but it remains essential for understanding data handling practices.
What is not different is that both Terms of Use specify that the Privacy Policy is not a part of the terms, but it remains essential for understanding data handling practices.
Europe Privacy Policy vs Privacy Policy
The general terms point out that the privacy policy is not part of the contractual framework between individuals and OpenAI. Despite this, the policies are still present and affect how OpenAI handles your data. In terms of which policies may be applicable, the Privacy Policy applies in general.
Since data protection regulation are dependent on local legal requirements, there are distinct privacy policies for specific locations. For example, if you reside in the EEA, Switzerland or the UK the Europe Privacy Policy is relevant and for US residents, the US Privacy Policy is applicable.
Do note that there are additional privacy policies for other locations too. This does however showcase that local legal requirements are taken into consideration. The main difference between these are the level of detail and connection to applicable data privacy regulation, which evidently does differ between Europe and the US.
OpenAI Contract Structure for Businesses
OpenAI Services Agreement Explained (Business Use)
As mentioned, businesses generally operate under separate terms. This is the same within OpenAI’s contractual framework through the OpenAI Services Agreement. This agreement applies to API customers and enterprise users and governs commercial deployment of OpenAI models. Most crucial is what type of user you are; i.e., if you are using a subscription plan for individuals (also Pro!), these business terms won’t apply. Because of this, it is relevant to check what type of subscription you use.
Unlike the Terms of Use, this agreement is structured as a commercial contract and is intended to be reviewed, negotiated, and managed by legal and procurement teams.
This agreement governs the key commercial and legal elements of the relationship. It addresses pricing and billing, defines permitted use of the models, allocates liability, and sets out intellectual property positions. In addition, it establishes how data is handled in a business context, typically in conjunction with a Data Processing Addendum.
What matters in practice is that this agreement fundamentally changes the risk allocation. It moves the relationship from a consumer-style framework to a business-to-business structure, where expectations around accountability, data protection, and commercial certainty are materially different. For organisations deploying AI at scale, this is the agreement that should anchor internal governance and contract review processes.
Service Terms (Product-Specific Rules)
On top of the primary contract sit the Service Terms, which apply to specific OpenAI products or functionalities. These are often overlooked because they are not always presented as standalone agreements. However, they are incorporated by reference and can materially affect how services are used in practice.
Service Terms typically define operational and technical conditions. For example, they may set limits on how APIs can be used, impose restrictions on certain use cases, or clarify how specific features function. In many cases, these terms translate directly into product-level constraints that business and technical teams must follow.
From a legal perspective, the key point is that Service Terms are binding once incorporated. From a business perspective, they often contain the rules that teams encounter day-to-day. Ignoring them creates a gap between what the contract allows and how the service is actually used.
Policies (Usage and Operational Rules)
In addition to contractual terms, OpenAI maintains a set of policies that apply across its services. These policies typically cover acceptable use, safety requirements, and operational restrictions. While they may not always read like traditional contractual clauses, they can still have binding effect when incorporated into the main agreement.
In practice, policies often contain the most immediate constraints on how ChatGPT and related services can be used. For example, they may prohibit certain categories of content, restrict high-risk use cases, or impose compliance-related obligations. These are not theoretical limitations—they directly affect how business teams deploy AI in real scenarios.
Another important feature is that policies are updated regularly. Because they are incorporated by reference, changes can apply without renegotiation. This creates a dynamic environment where compliance is not a one-time exercise but an ongoing process.
Privacy Policy vs Data Processing Addendum
A common source of confusion is the difference between the Privacy Policy and the Data Processing Addendum (DPA). Although both relate to data, they serve fundamentally different purposes.
The Privacy Policy explains how OpenAI handles data in general terms. It is primarily aimed at transparency and user information, particularly in a consumer context. However, it does not typically form part of the contractual framework in the same way as other documents.
The Data Processing Addendum, by contrast, is a contractual document. It applies in business relationships and governs how personal data is processed on behalf of the customer. It defines roles such as controller and processor, sets out security measures, and addresses regulatory requirements such as GDPR compliance.
For organisations, the distinction is critical. The Privacy Policy tells you what happens in practice, while the DPA defines what OpenAI is legally required to do. Relying on the former instead of the latter can lead to incorrect assumptions about compliance and risk allocation.
Does ChatGPT Train on Your Data?
One of the most frequently asked questions is whether ChatGPT trains on your data. The answer depends on which terms apply.
Under consumer use, ChatGPT may use inputs and outputs to improve its models, unless users actively opt out where that option is available. This reflects the default structure of many consumer AI services, where data contributes to ongoing model development.
Under the OpenAI Services Agreement, the position is different. In a business context, customer data is generally not used for training purposes. This distinction is not merely technical—it is contractual.
In practice, this creates a clear risk scenario. Employees may use ChatGPT under consumer terms, while the organisation assumes that enterprise-level protections apply. The tool is the same, but the legal framework is not. As a result, understanding which terms apply is essential for managing both data risk and internal compliance.
The data protection layer’s place
So, what other terms may be applicable as well? Well, the Data Processing Addendum sits alongside the OpenAI Services Agreement through reference. It governs how OpenAI processes personal data on behalf of the customer. Crucially, the DPA, not the general privacy policy nor the location specific privacy policies, creates the contractual data protection obligations. Business teams often confuse the two, but legally they serve very different purposes.
On one hand, the Data Processing Addendum is critical for GDPR and similar regimes and defines roles (controller vs processor), sets out processing instructions and security measures, addresses cross-border transfers and sub-processors. This is relevant as it sets out which obligations your organization shall follow in terms of data privacy. On the other hand, the privacy policies is relevant as it sets out what kind of protection OpenAI offers to their customers. That refers to the actual users, for example employees in your company.
How To Handle AI Usage
Defining Key Documents and Processes
AI usage intersects with several contractual touch-points like the general terms and data handling policies. Therefore, hidden clauses allowing various things may be applicable. Understanding of overarching responsibilities and rights, like how data is used, and how outputs are verified is recommended. For example, companies should ensure that no confidential or client data may be submitted to public AI interfaces unless approved safeguards exist.
Connecting Legal, Sales, and Procurement Functions
In many organizations, sales teams use AI for proposal generation while legal reviews contracts separately. Procurement teams vet vendors but may not assess AI clauses. Consequently, a misalignment arises. Depending on what terms apply, there may be a risk that confidential information is shared with the AI company. Therefore, collaboration between for example Sales and Legal is key to ensure that OpenAI’s terms, and similar clauses from other AI providers, are reviewed beforehand.
Balancing Flexibility and Risk Reduction
AI adoption should not paralyze innovation. Instead, companies can create “approved use” guidelines outlining permissible AI tools and inputs. This approach preserves flexibility for business teams while embedding guardrails against data misuse. Moreover, including AI-specific language in supplier and client contracts ensures accountability.
Key Takeaways
- OpenAI’s contract structure is layered by multiple documents,
- Different OpenAI terms apply to EU individuals, non-EU individuals, and businesses,
- Policies and addenda often contain the most practical obligations,
- Understanding the structure improves both commercial and legal outcomes, and
- Proactive mapping and monitoring reduce risk and delays.
Frequently Asked Questions
Q: When should we use the OpenAI Services Agreement instead of the Terms of Use?
A: When ChatGPT or OpenAI services are used in a business context, especially via APIs or enterprise solutions. This ensures appropriate commercial and data protection terms apply.
Q: What is the real risk if we get this wrong?
A: The main risk is a mismatch between assumed protections and actual terms. This can lead to unintended data use, limited liability coverage, and compliance issues.
Q: Who should own this internally?
A: Typically legal and procurement should define the framework, but IT and business teams must be involved to ensure actual usage aligns with approved terms.
Q: Does this apply differently across jurisdictions?
A: Yes. For example, EEA-specific Terms of Use and privacy frameworks may apply depending on location. This affects enforcement and regulatory compliance.
Q: Do we need tailored legal advice or are standard terms enough?
A: For low-risk use cases, standard terms may be sufficient. However, for enterprise use or integration into products, tailored review is recommended.
Conclusion & Call to Action
Understanding which subscriptions equals what applicable contract is no longer optional for organisations using SaaS or AI at scale. It directly affects risk allocation, commercial commitments, and strategic flexibility. At AMST Legal, we regularly support clients in reviewing, negotiating, and operationalising AI and SaaS contracts, either on a project basis or as interim in-house counsel.
If you want to better understand how OpenAI’s contracts affect your business, or if you are preparing for negotiations, audits, or customer discussions, we can help. Visit amstlegal.com to learn more or book a consultation today, or email info@amstlegal.com.
Note: this an updated draft of the article of January 2025: Ultimate Guide how ChatGPT, Perplexity and Claude use Your Data.

DeepSeek – Is your Data Safe? Everything You Need to Know
In my previous article we examined how ChatGPT, Perplexity and Claude uses your data (AI data use). We also mentioned the potential risks of sharing confidential or proprietary information – and how to avoid these risks. It is clear that not all tools offer the same safeguards regarding data privacy, security, and legal protections. We will therefore continue comparing AI models. This week a focus on the AI model DeepSeek. See below our Article ‘DeepSeek – Is your Data Safe? Everything You Need to Know’.
DeepSeek was unknown to most people outside of the People’s Republic of China (“PRC“) until this week. In the course of one week it has however gained immensely in popularity. It is yet another AI-driven platform, but there are important differences with the other well-known AI models. DeepSeek is currently challenging AI models like ChatGPT and Gemini in capabilities unexpected until yesterday. In this article, we will explore DeepSeek’s Privacy Policy & Terms of Use. We will also handle issues such as personal data storage, AI model training and jurisdiction. If you’re wondering whether you can safely use DeepSeek for personal or professional tasks, read on to discover the key facts, risks and best practices.
This article has been written at the start of the broad use of DeepSeek. It is therefore work in progress, based on first information gathered.
What We’ll Cover
- DeepSeek Overview: Short explanation of the platform and why are people interested in it.
- Privacy Policy Highlights: Including details on storing personal data, especially full names and addresses.
- Location of Data: How and why user data may end up on servers in the People’s Republic of China.
- Terms of Use: Whether DeepSeek incorporates your content into training its AI models—and what that means for you.
- Data Privacy in China: The local regulatory environment and how it differs from GDPR or CCPA.
- Confidentiality: Potential risks if you’re handling sensitive or proprietary information.
- Final Advice: How to proceed if you’re considering using DeepSeek, plus some general cautionary steps.
1. DeepSeek Explained
New AI Model
DeepSeek is a cutting-edge large language model (LLM) similar to ChatGPT and Gemini. It is developed by a Chinese AI company with the full name ‘Hangzhou DeepSeek Artificial Intelligence Co., Ltd., and Beijing DeepSeek Artificial Intelligence Co., Ltd.’. It is designed to tackle a range of complex tasks with impressive efficiency according the latest tests. According to Google Gemini its powerful AI shines in several key areas:
- Math Whiz: DeepSeek excels at mathematical reasoning and problem-solving, often outperforming other models.
- Logic Master: DeepSeek handles complex, multi-step logical reasoning with ease.
- Code Conjurer: DeepSeek understands and generates code in various programming languages, making it a valuable tool for developers.
- Conversation Starter: DeepSeek is a natural language expert, capable of engaging in coherent and contextually relevant conversations.
- Global Communicator: DeepSeek is trained on diverse linguistic data, offering some level of multilingual support.
Consequences Stock Market
On 26 January 2025 there was even a big shake up in the stock market due to Deep Seek. US stocks plummeted as traders fled the tech sector and erased more than $1 trillion in market cap amid panic over the introduction of DeepSeek. The S&P 500 nearly 1.5% lower, while the tech-heavy Nasdaq Composite had shed more 3% by the end of the day. DeepSeek roiled stock futures after the AI model was said to outperform OpenAI’s ChatGPT in several tests. The losses gathered momentum after DeepSeek became the most downloaded app on Apple’s App Store in the US on 26 January.
Source: Business insider.
A Growing Global Market
As AI popularity expands worldwide, companies outside the U.S. and Europe (especially China) are developing their own solutions. DeepSeek is notable because it may offer high-speed performance and robust Chinese language capabilities. This makes it attractive to users with specialized language needs. However, these benefits come with a different legal framework, which can pose challenges for those used to Western data protection standards.
It has also been reported that DeepSeek is able to offer similar services and results as ChatGPT, Gemini, etc. for a fraction of the cost. This has greatly fueled popularity of the new AI model.
2. DeepSeek’s Privacy Policy: Personal Data Collection
Amongst others, according to a review of DeepSeek’s publicly accessible Privacy Policy, the platform collects a wide range of personal information. Qoute: “When you create an account, input content, contact us directly, or otherwise use the Services, you may provide some or all of the following information:
- Information When You Contact Us. When you contact us, we collect the information you send us, such as proof of identity or age, feedback or inquiries about your use of the Service or information about possible violations of our Terms of Service (our “Terms”) or other policies.
- Profile information. We collect information that you provide when you set up an account, such as your date of birth (where applicable), username, email address and/or telephone number, and password.
- User Input. When you use our Services, we may collect your text or audio input, prompt, uploaded files, feedback, chat history, or other content that you provide to our model and Services.
Additionally DeepSeek stores (i) Automatically Collected Information like technical information, usage information, cookies, payment information and (ii) information from other sources like login, signup or linked information.
Where Is Information Stored
DeepSeek explicitly states:
“The personal information we collect from you may be stored on a server located outside of the country where you live. We store the information we collect in secure servers located in the People’s Republic of China.
Where we transfer any personal information out of the country where you live, including for one or more of the purposes as set out in this Policy, we will do so in accordance with the requirements of applicable data protection laws.”
For many users – especially those in countries with stringent privacy regulations – this is significant. Your legal recourse to access, delete or restrict your data might be limited once it’s hosted on servers in the PRC.
How Is This Data Stored and Processed?
While the Privacy Policy mentions “secure servers,” it is not clear how they deal with specific practices such as:
- Encryption: Are your data and prompts encrypted at rest or in transit?
- Third-Party Sharing: How widely is your data shared for analytics or collaboration?
- Data Deletion: What happens if you decide to close your account or remove certain information?
- Data Security: How are the servers protected against e.g. cyberattacks.
If you’re accustomed to GDPR (EU Data Privacy Regulation) or CCPA (California Data Privacy Regulation), you may be disappointed by the lack of clearly defined user rights (like the right to be forgotten or the right to data portability). It remains to be seen how these matters are covered by DeepSeek. Especially from a regulatory point of view – data privacy, data security and now also AI (see the EU AI Act).
There are many more aspects that are very interesting in the DeepSeek Privacy Policy, but for the purposes of this article this would be too much information to touch on all aspects.
3. DeepSeek’s Terms of Use: Model Training & Governing Law
DeepSeek’s Terms of Use do mention that the AI model will only use your Inputs in specific cases. It is however not exactly clear how broad this should be read. See part below in blue. The terms also offer a way for its customers to inform DeepSeek that they refuse DeepSeek to allow to use their Input data.

Potential Risks for Confidential Information
When adding client documents, proprietary research, or any private data as always be mindful. As far as we are aware at this moment:
- No Guarantee of Confidentiality: There is no explicit promise to keep sensitive data confidential.
- Future AI Outputs: The model might inadvertently reveal or be influenced by your confidential info.
- Irreversible Submission: As DeepSeek’s Terms of Use do not mention how long DeepSeek will store your data, this will allow indefinite use of your data.
- Unclear use of Input: it is not exactly clear how and in which cases your Inputs will be used to create Outputs or to train the model. It is likely and we should assume that DeepSeek uses your Input to train their AI model.
Governing Law and Jurisdiction
Next, let’s review the terms regarding governing law and jurisdiction, meaning the laws that govern the use of DeepSeek and where you will need to go to court in case of litigation with DeepSeek. DeepSeek clarifies this as follows in the Terms of Use:
9. Governing Law and Jurisdiction
9.1 The establishment, execution, interpretation, and resolution of disputes under these Terms shall be governed by the laws of the People’s Republic of China in the mainland.
9.2 If negotiation fails in resolving disputes, either Party may file a lawsuit with a court having jurisdiction over the location of Hangzhou DeepSeek Artificial Intelligence Co., Ltd.
This means:
- The laws of the People’s Republic of China govern all legal disputes.
- Chinese courts in Hangzhou, PRC, will handle any lawsuits.
- Even though it is stated in the terms that DeepSeek will comply with applicable laws, research still needs to be done whether they will comply with GDPR, CCPA or other foreign regulations.
4. Data Privacy in China
In the EU and US there have been large initiatives since 2018 with respect to extensive legislation relating to the protection of data privacy and data security. In the coming years there will even be more regulations in connection hereto. See our article ‘Six New EU Regulations – like the AI Act – Explained‘.
Regulatory Differences
While China has its Personal Information Protection Law (PIPL), it doesn’t mirror the scope or depth of frameworks like GDPR or CCPA or the other regulations mentioned above – as far as we are aware but we are not lawyers or legal advisors versed in PRC laws.
Implications for International Users
If you reside outside China:
- Limited Recourse: You might find it harder to challenge data privacy & security issues in a Chinese court.
- Compliance Gaps: The data privacy and data security protections you are used to under EU or U.S. law may not apply here.
- Cross-Border Transfers: Even if the Privacy Policy mentions meeting local regulations, these could be PRC regulations that differ significantly from your home country’s standards.
5. Which Data Not to Share in AI Models
As we stated in our article with respect ChatGPT, Gemini and Perplexity, apply common sense and caution when adding data to any online AI model. This could be different for local models – depending on the security measures taken by the AI model.
Avoid sharing for example:
- Confidential details (client, business or family member names, private letters, contracts & strategies).
- Personally identifiable information (PII) (addresses, phone numbers, medical records).
- Proprietary or business-critical data (unreleased products, prices, financials).
- Sensitive materials (health info, internal memos, or business & personal).
- Data protected by Applicable Law (copyright, illegal data, government data).
If you must work with potentially sensitive text, we recommend considering the following:
- anonymizing the data first,
- using an enterprise-level AI solution where the Terms of Use prohibit using your content for model training. This doe not seem to be possible for DeepSeek, or
- an ‘on-premise’ AI model that anonymizes data.
6. Bringing It All Together
DeepSeek represents an interesting expansion of the AI landscape, especially for those who require strong Chinese language capabilities or want to explore AI solutions outside typical Western providers. However, its legal environment, data storage location, and governing jurisdiction all point to a platform that may not uphold the same privacy or confidentiality standards you’d expect under GDPR or CCPA.
This doesn’t mean DeepSeek is without merit. You should approach it with open eyes and informed caution. If you have critical confidentiality needs or work in a heavily regulated sector, it is wise to look elsewhere or secure a specialized enterprise agreement that explicitly addresses data protection concerns. For casual or non-sensitive uses, DeepSeek could be a helpful AI resource. As always, be mindful of what you submit and how it could be stored and potentially accessed under Chinese law.
7. Final Thoughts
AI is transforming the way we work – but it’s also transforming how data can move beyond our control. It is advised to think twice before you add content to any AI (LLM) Tool and actively keep track of how your content is used by any AI tool.
As always, we need to stay informed, be cautious and be proactive. That way, you can use the power of AI without compromising your most sensitive information. Keep an eye out for our upcoming in-depth articles on other AI models. We will also cover AI policies that can guide you and your team toward ethical and secure usage of these exciting new technologies.
Disclaimer: This article is a research project, provides general information about AI data usage and does not constitute legal advice.
If you have any further questions about the above, contact me via lowa@amstlegal.com or set up a meeting directly here .
To read more on this topic here is Ultimate Guide how ChatGPT, Perplexity and Claude use Your Data, Anthropic’s Claude AI Updates – Impact on Privacy & Confidentiality, South Korea spy agency says DeepSeek ‘excessively’ collects personal data, Berlin’s data protection commissioner reports the AI app DeepSeek to Apple and Google in Germany as containing illegal content, Is DeepSeek safe to use?